Getting started
Introduction
Kubernetes, souvent abrégé en K8s (le 8 représente les lettres entre le K et le s), est une plateforme open-source d’orchestration de conteneurs. Elle permet de déployer, mettre à l’échelle, et gérer automatiquement des applications conteneurisées dans un environnement distribué. Aujourd’hui K8s se présente comme l’un des standards de l’orchestration de conteneurs.
Créé par Google en 2014 (issu de leur expérience interne avec Borg), Kubernetes est maintenant maintenu par la Cloud Native Computing Foundation (CNCF). Plus de 75 % des projets de la CNCF sont écrits en Go. Kubernetes, Terraform, Docker, Helm, Istio, et de nombreux autres outils de la CNCF sont développés en Go.
🎯 Objectifs principaux de Kubernetes
Kubernetes a pour mission de :
-
Automatiser le déploiement et le redémarrage des applications
-
Gérer la montée en charge (scalabilité automatique)
-
Isoler, organiser, et superviser des groupes de conteneurs
-
Fournir des services réseaux internes et externes
-
Gérer la configuration et les secrets
-
Orchestrer des mises à jour progressives (rolling updates)
Pourquoi utiliser Kubernetes ?
Tant que votre application conteneurisée est déployée sur une seule machine, et si cela suffit niveau disponibilité, il n’est pas nécessaire d’utiliser Kubernetes. Cependant, K8s devient indispensable dans les cas suivants :
-
Redémarrage manuel d’un service en cas de crash
-
Scripts maison pour gérer le déploiement
-
Scalabilité difficile
-
Difficulté à gérer l’état d’une application distribuée
-
Réseau et sécurité mal intégrés
Ce que Kubernetes n’est pas
-
Un système de build d’images (→ utilise Docker, Buildah, etc.)
-
Un orchestrateur de machines virtuelles (c’est pour les conteneurs)
-
Une solution de CI/CD (mais il s’intègre très bien avec des outils comme GitLab CI, ArgoCD, etc.)
Prérequis
Kubernetes (K8s) s’appuie fortement sur des notions de réseau. Au fil de votre apprentissage vous serez surement confronté aux notions ci dessous :
- L’adressage IP (réseaux privés/publics)
- Les ports, protocoles TCP/UDP
- Le fonctionnement du DNS interne
- Le routage et le load balancing
- Une familiarité avec
iptables(pare-feu Linux) est un plus
🐳 Docker comme base
Docker peut être perçu comme une technologie introductive.
Kubernetes réutilise les concepts de conteneurs, mais en les étendant à l’échelle du cluster :
- Orchestration
- Répartition de charge
- Résilience et auto-réparation
📦 Distributions Kubernetes
Il existe plusieurs distributions de Kubernetes, certaines proposées par des fournisseurs cloud privés, d’autres open source plus légères adaptées à l’apprentissage ou à l’edge computing, comme K3s.
Voici quelques exemples de distributions courantes :
| Distribution | Particularité |
|---|---|
| GKE (Google) | Version managée par Google Cloud, payante |
| EKS (AWS) | Version managée sur Amazon |
| AKS (Azure) | Version managée sur Microsoft Azure |
| K3s | Distribution légère, idéale pour edge computing ou dev |
| MicroK8s | Version légère proposée par Canonical (Ubuntu) |
| Minikube | Déploiement local pour apprentissage ou tests |
| OpenShift | Distribution Red Hat, avec sécurité renforcée et CI/CD intégrée |
🐧 Connaissances système Linux
La gestion des Pods et de l’environnement Kubernetes nécessite des compétences en administration système Linux.
Ces compétences sont utiles pour :
- Configurer les différents nœuds (serveurs/agents)
- Débugger des erreurs système ou réseau
- Surveiller les processus et services critiques
Compétences recommandées :
- Utilisation de la ligne de commande (bash,
ssh,scp) - Gestion des services (
systemctl,journalctl) - Manipulation de fichiers (
vim,nano,cp,mv) - Surveillance système (
ps,top,htop,kill)
Architecture
Serveurs et agents
Un nœud de serveur est défini comme un hôte exécutant la k3s servercommande, avec des composants de plan de contrôle et de banque de données gérés par K3s. Un nœud d’agent est défini comme un hôte exécutant la k3s agentcommande, sans aucun composant de banque de données ou de plan de contrôle. Les serveurs et les agents exécutent le kubelet, l’environnement d’exécution du conteneur et le CNI. Consultez la documentation sur les options avancées pour plus d’informations sur l’exécution de serveurs sans agent.
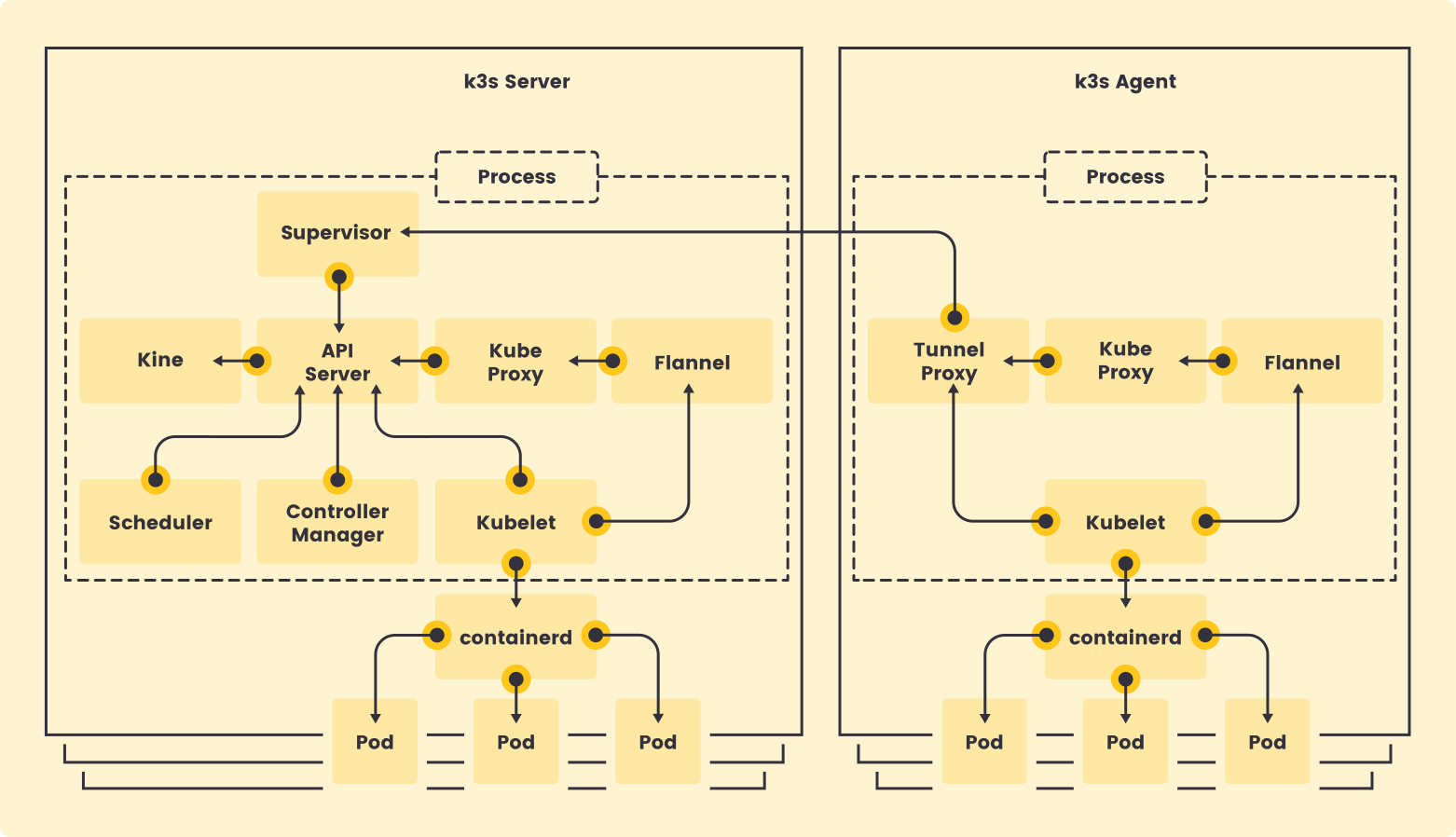
Cas concret de la docucmentation
Les nœuds d’agent sont enregistrés avec une connexion WebSocket initiée par le k3s agentprocessus, et cette connexion est maintenue par un équilibreur de charge côté client, exécuté dans le cadre du processus d’agent.
Initialement, l’agent se connecte au superviseur (et à kube-apiserver) via l’équilibreur de charge local sur le port 6443. L’équilibreur de charge gère une liste de points de terminaison disponibles.
Le point de terminaison par défaut (initialement unique) est initialisé par le nom d’hôte de l’ —serveradresse. Une fois connecté au cluster, l’agent récupère une liste d’adresses kube-apiserver à partir de la liste des points de terminaison du service Kubernetes dans l’espace de noms par défaut. Ces points de terminaison sont ajoutés à l’équilibreur de charge, qui maintient ensuite des connexions stables à tous les serveurs du cluster, fournissant ainsi une connexion à kube-apiserver qui tolère les pannes de serveurs individuels.
Les agents s’enregistreront auprès du serveur à l’aide du secret du cluster de nœuds, ainsi que d’un mot de passe généré aléatoirement pour le nœud, stocké dans
/etc/rancher/node/password. Le serveur stockera les mots de passe des nœuds individuels sous forme de secrets Kubernetes,
et toute tentative ultérieure devra utiliser le même mot de passe. Les secrets des mots de passe des nœuds sont stockés dans l’ kube-systemespace de noms, avec des noms utilisant le modèle
Si le /etc/rancher/node_répertoire d’un agent est supprimé ou si vous souhaitez rejoindre un nœud sous un nom existant, supprimez-le du cluster. Cela effacera l’ancienne entrée du nœud et son mot de passe secret, et permettra au nœud de rejoindre le cluster.
Si vous réutilisez fréquemment des noms d’hôtes, mais que vous ne parvenez pas à supprimer les mots de passe secrets des nœuds, un identifiant de nœud unique peut être automatiquement ajouté au nom d’hôte en lançant les serveurs ou agents K3s à l’aide de l’ —with-node-idoption. Lorsque cette option est activée, l’identifiant de nœud est également stocké dans /etc/rancher/node/.
Control Panel
Lorsque vous utilisez kubectl pour gérer le cluster, en back-end, vous communiquez avec le serveur d’API via des API REST HTTP. Cependant, les composants internes du cluster, comme le planificateur, le contrôleur, etc., communiquent avec le serveur d’API via gRPC .
La communication entre le serveur API et les autres composants du cluster s’effectue via TLS pour empêcher tout accès non autorisé au cluster.
Etcd
Kubernetes est un système distribué qui nécessite une base de données distribuée performante, telle qu’etcd, pour fonctionner efficacement. etcd prend en charge la nature distribuée de Kubernetes en agissant à la fois comme un service de découverte (back-end) et comme une base de données clé-valeur. On peut la considérer comme le cerveau du cluster Kubernetes.
Kubelet (agent)
Mini orchestrateur qui ne gère pas le runtime.
Kubelet est un composant agent qui s’exécute sur chaque nœud du cluster. Il ne s’exécute pas en tant que conteneur mais plutôt en tant que démon, géré par systemd.
Voici quelques-uns des éléments clés de kubelet.
Kubelet utilise l’interface gRPC CRI (container runtime interface) pour communiquer avec le runtime du conteneur. Il expose également un point de terminaison HTTP pour diffuser des journaux et fournit des sessions d’exécution pour les clients. Utilise l’interface de stockage de conteneur (CSI) gRPC pour configurer les volumes de blocs. Il utilise le plugin CNI configuré dans le cluster pour allouer l’adresse IP du pod et configurer les routes réseau et les règles de pare-feu nécessaires pour le pod.
Containerd
containerd est un runtime de conteneurs développé par Docker qui gère le cycle de vie d’un conteneur sur une machine physique ou virtuelle (c’est-à-dire un hôte). Il crée, lance, arrête et supprime les conteneurs. Il peut également extraire des images de conteneurs des registres, monter le stockage et activer la mise en réseau d’un conteneur.
En février 2019, containerd est devenu un projet officiel au sein de la Cloud Native Computing Foundation (CNCF), au même titre que Kubernetes, Prometheus, Envoy et CoreDNS.
Proxy Kube
Kube-proxy est un démon qui s’exécute sur chaque nœud en tant que daemonset . Ce composant proxy implémente le concept de services Kubernetes pour les pods (DNS unique pour un ensemble de pods avec équilibrage de charge). Il utilise principalement les proxys UDP, TCP et SCTP et ne comprend pas HTTP.
Lorsque vous exposez des pods à l’aide d’un service (ClusterIP), Kube-proxy crée des règles réseau pour envoyer le trafic vers les pods backend (points de terminaison) regroupés sous l’objet Service. Autrement dit, l’équilibrage de charge et la découverte de services sont gérés par le proxy Kube.
Vous ne pouvez pas envoyer de ping au ClusterIP car il est uniquement utilisé pour la découverte de services, contrairement aux IP de pod qui sont pingables.
Concepts & Composants
Namespaces
Les namespaces permettent d’isoler les ressources dans un cluster K8s.
- Sans namespace explicite, les ressources vont dans le
default. - Commande :
kubectl get allne montre que les ressources du namespace courant. - Utilise
kubectl get all --all-namespacespour tout afficher.
Pods
- Un pod est l’unité de base de Kubernetes.
- Contient un ou plusieurs conteneurs partageant IP, réseau et stockage.
- Géré automatiquement : s’il crash, il est relancé.
- Créé par des objets comme Deployment, DaemonSet, etc.
ClusterIP
ClusterIP est le type par défaut des Services. Il expose un Pod à l’intérieur du cluster uniquement (pas à l’extérieur). Très utilisé pour la communication interservices, même si on ne le voit pas toujours directement.
Objets principaux
| Objet | Rôle |
|---|---|
| Pod | Unité d’exécution contenant un ou plusieurs conteneurs. |
| Deployment | Crée et gère des pods réplicables (ex: frontend, API, workers), permet de configurer les replicaSet (on les configure tjrs les replica, jamais les replicaSet). |
| DaemonSet | 1 pod par nœud (ex: monitoring, agent de log). |
| CronJob | Lance un pod à intervalle régulier (tâches planifiées). |
| StatefulSet | Gère des pods avec identité stable (ex: base de données). |
| Service | Point d’accès stable vers un ou plusieurs pods. |
| Ingress | Reverse proxy pour exposer HTTP(S) avec routage par chemin/domaine. |
| Secret | Stocke des infos sensibles (mdp, tokens). |
| ConfigMap | Stocke des configs non sensibles (variables, fichiers). |
Types de Services
| Type de service | Accessible depuis | Description rapide |
|---|---|---|
ClusterIP | Interne au cluster | Par défaut. Utilisé pour les communications internes entre pods. |
NodePort | IP de chaque nœud | Ouvre un port statique (<IP-node>:port). Simplicité mais peu flexible. |
LoadBalancer | Internet (Cloud Provider) | Crée un vrai Load Balancer (cloud uniquement ou MetalLB en local). |
ExternalName | Redirection DNS | Redirige vers un DNS externe (ex: api.example.com). |
| Ingress | HTTP(S) unique | Reverse proxy pour exposer plusieurs services via un seul point d’entrée. |
ConfigMap et Secret
ConfigMap, pour des données non sensibles. Secret, utilisée pour des données sensibles, comme des mots de passe, des clés API ou des certificats. Les données sont encodées en base64, ce qui n’est pas un véritable chiffrement. Elles ne sont donc pas réellement sécurisées au repos (une fois stockées), mais c’est une mesure minimale de protection.
Pour aller plus loin il est possible de configurer k8s pour un réel chiffrement exemple:
apiVersion: apiserver.config.k8s.io/v1kind: EncryptionConfigurationresources: - resources: - secrets providers: - aescbc: keys: - name: key1 secret: <clé AES en base64> - identity: {}Ici on utilise aescbc (chiffrement AES) dans les étapes de stockage des clé. K8s va d’abord passer par ce provider, en utilisant une clé générée au préalable pour chiffrer notre secret. (cf voir cours sur chiffrement)
LoadBalancer
Un Service de type LoadBalancer est un objet Kubernetes qui permet d’exposer un service du cluster à l’extérieur, en lui attribuant une adresse IP externe (publique ou privée). Cette adresse est généralement fournie par un cloud provider ou par une solution interne comme MetalLB dans un environnement on-premise (sur site). Ce type de service agit comme une passerelle réseau publique : il redirige le trafic entrant vers les Pods associés au service à l’intérieur du cluster. Il n’est pas responsable de planifier les Pods (ce rôle revient au Scheduler), ni de faire du routage applicatif complexe (ce rôle revient souvent à un Ingress Controller).
Ainsi le LoadBalancer permet à des utilisateurs ou des systèmes extérieurs au cluster d’accéder à un service spécifique, sans intervenir dans la gestion des Pods ni dans la création de réplicas.
📝 En local, utilise MetalLB pour simuler ce comportement.
Exemple :
À travers cette configuration, le LoadBalancer va associer une IP publique au port 80 et rediriger le trafic vers l’application interne nommée my-app, qui écoute sur le port 3000 dans les pods ciblés.
apiVersion: v1 kind: Service metadata: name: my-app-service spec: type: LoadBalancer selector: app: my-app ports: - port: 80 # Port externe targetPort: 3000LoadBalancer & Garbage collector
Dans le cas général, les ressources de load balancer associées chez le cloud provider devraient être automatiquement supprimées peu de temps après la suppression d’un Service de type LoadBalancer. Cependant, il est connu que divers cas limites (corner cases) peuvent entraîner l’apparition de ressources orphelines (non supprimées) après la suppression du Service associé.
Pour éviter cela, une protection par Finalizer a été introduite pour les Services LoadBalancer. Grâce à l’utilisation des finalizers, une ressource Service ne pourra jamais être supprimée tant que les ressources load balancer correspondantes n’ont pas été supprimées également.
Concrètement, si un Service est de type LoadBalancer, le service controller lui attache automatiquement un finalizer nommé :
service.kubernetes.io/load-balancer-cleanup.Ce finalizer ne sera supprimé qu’après le nettoyage effectif de la ressource de load balancer. Cela permet d’éviter les ressources orphelines, même dans des corner cases comme un crash du service controller.
Ingress (et pourquoi le préférer)
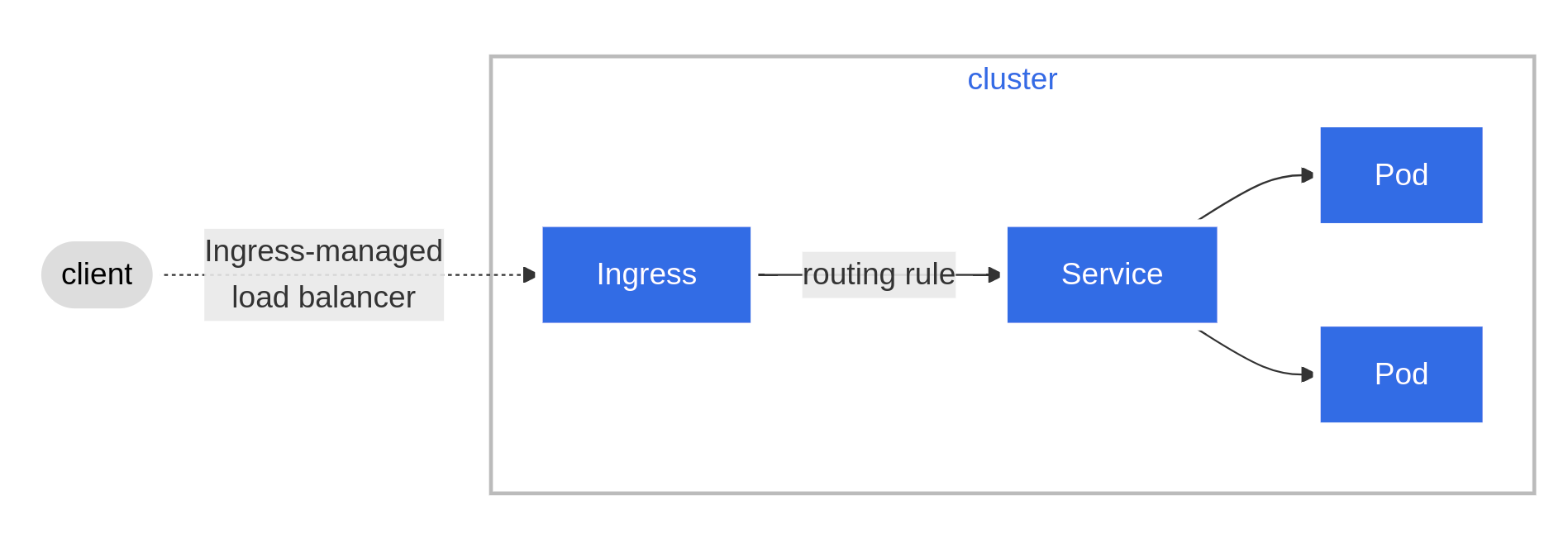
Ingress
Rendez votre service réseau HTTP (ou HTTPS) accessible en utilisant un mécanisme de configuration “protocol-aware”, qui comprend les concepts web comme les URI, hostnames, paths, etc. Le concept d’Ingress vous permet de mapper le trafic vers différents backends selon des règles que vous définissez via l’API Kubernetes.
Un Ingress expose des routes HTTP et HTTPS depuis l’extérieur du cluster vers des services à l’intérieur du cluster. Le routage du trafic est contrôlé par des règles définies dans la ressource Ingress.
Un Ingress peut être configuré pour fournir aux Services des URLs accessibles de l’extérieur, faire du load balancing du trafic, gérer la termination SSL / TLS, et offrir un virtual hosting basé sur le nom de domaine.
Un Ingress controller est responsable de la mise en œuvre de l’Ingress, généralement à l’aide d’un load balancer, mais il peut aussi configurer votre edge router (mini routeur physique) ou d’autres frontends pour aider à gérer le trafic.
Un Ingress n’expose pas de ports ou de protocoles arbitraires. Pour exposer des services autres que HTTP et HTTPS sur Internet, on utilise typiquement un Service de type NodePort ou LoadBalancer.
Exemple ingress ressource
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: minimal-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: / # routage externe:interne pour le ingressController spec: ingressClassName: nginx-example # liens issu du nom du ingressController rules: - http: # les requetes http pointant vers /testpath paths: # seront redirigé vers le service se nommant name:80 - path: /testpath pathType: Prefix backend: service: name: test port: number: 80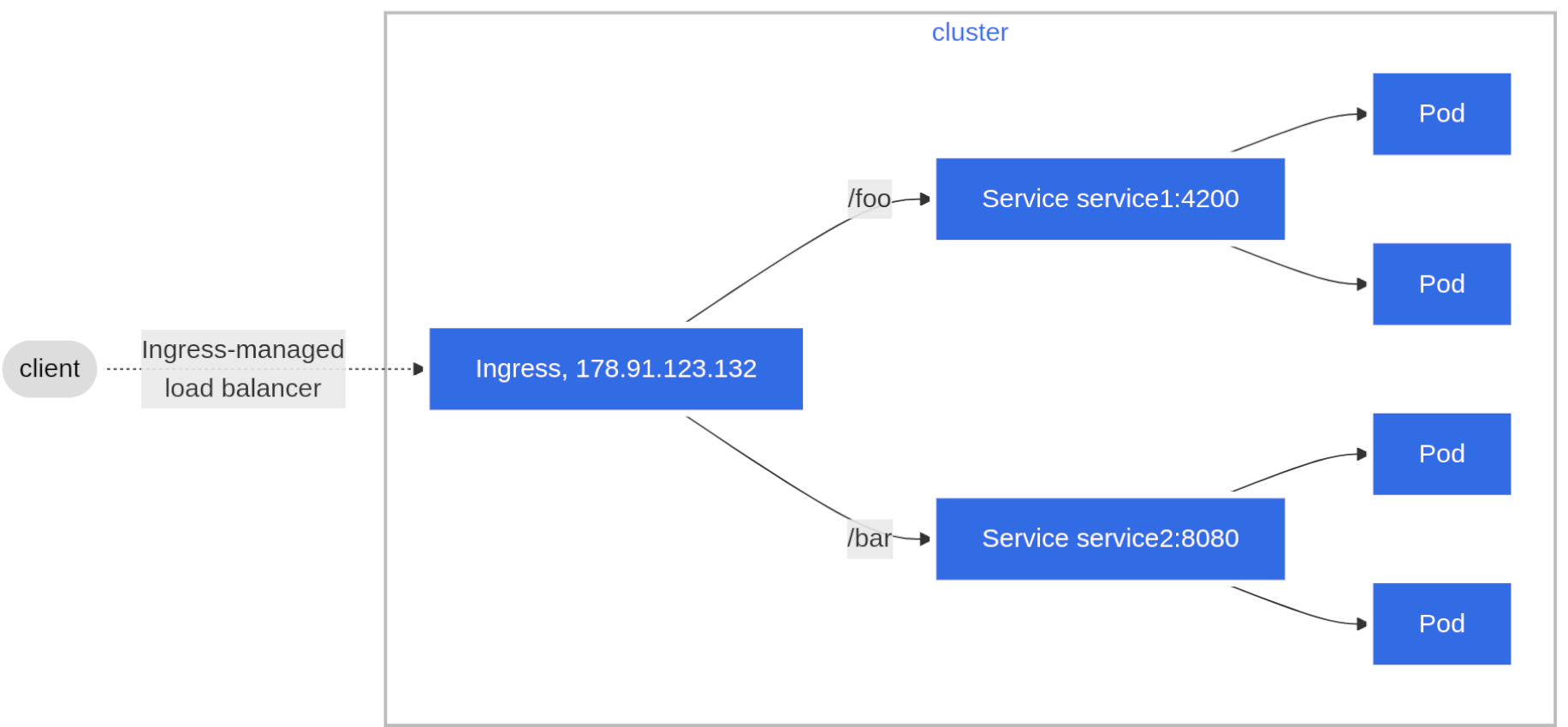
Ingress Controller
Pour qu’un Ingress fonctionne dans votre cluster, un ingress controller doit être en cours d’exécution. Vous devez sélectionner au moins un ingress controller (environ ~31 controller officiels) et vous assurer qu’il est correctement configuré dans votre cluster.
| Ingress Controller | Remarques |
|---|---|
| NGINX | Le plus courant, stable, très utilisé |
| Traefik | Moderne, léger, dynamique |
| HAProxy | Performant, très configurable |
| Contour | Basé sur Envoy |
| Istio Gateway | Si tu utilises Istio comme service mesh |
| AWS ALB | Intégré dans l’infrastructure AWS |
| GKE Ingress | Fournisseur Google Cloud |
| … | … |
Ingress = Objet Kubernetes Ingress Controller = Pod qui implémente cet objet (ex : nginx, traefik)
| Option | ✅ Avantages | ❌ Inconvénients |
|---|---|---|
| NodePort | Facile pour tester en local | Moins sécurisé, peu flexible |
| LoadBalancer | Propre en cloud | Cher (un LB par service), inutile sans cloud |
| Ingress | Idéal pour exposer plusieurs services | Nécessite un Ingress Controller (NGINX, Traefik…) |
Ingress = Le choix moderne
- Un seul point d’entrée
- Routage par chemin (
/api,/ws) ou domaine (api.monsite.com) - Support du HTTPS, Let’s Encrypt, cert-manager
- Scalable, maintenable, propre
ConfigMap / Secret
| Ressource | Utilité |
|---|---|
| ConfigMap | Paramètres non sensibles (env, fichiers config) |
| Secret | Données sensibles (tokens, mdp…) |
exemples
ConfigMap
apiVersion: v1 kind: ConfigMap metadata: name: example-config data: # Données non sensibles sous forme clé/valeur database_host: "db.example.com" database_port: "5432" feature_flag: "true"Secret
apiVersion: v1 kind: Secret metadata: name: example-secret type: Opaque data: # Données sensibles encodées en base64 username: YWRtaW4= # "admin" encodé en base64 password: c2VjcmV0MTIz # "secret123" encodé en base64implémentation Pod
apiVersion: v1 kind: Pod metadata: name: example-pod spec: containers: - name: my-container image: nginx env: - name: DB_HOST valueFrom: configMapKeyRef: name: example-config key: database_host - name: DB_USER valueFrom: secretKeyRef: name: example-secret key: usernameStockage : Volume / PVC
- Un pod est éphémère, donc ses données disparaissent à sa mort.
- Pour persister les données :
- Utilise un
PersistentVolume - Requis :
PersistentVolumeClaim(PVC) pour s’y connecter
- Utilise un
- Utilisé avec
StatefulSetou pour les bases de données.
Un pod peut se configurer avec un PVC pour obtenir une persistance de donées. Par exemple, ici je créer un PVC
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi # Taille demandée storageClassName: standard # Classe de stockage (selon ton cluster)Que je nomme my-pvc
et que j’associe a mon pod dans volumes:
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx volumeMounts: - name: my-storage mountPath: /usr/share/nginx/html # chemin dans le conteneur volumes: - name: my-storage persistentVolumeClaim: claimName: my-pvc # référence au PVC*Le volume peut être monté en lecture-écriture par un seul noeud à la fois (sinon aller voir du coté de ReadWriteMany) *
Probes
- Liveness Probe : redémarre le conteneur s’il ne répond plus.
- Readiness Probe : signale si le conteneur est prêt à recevoir du trafic.
- Important pour la santé et la stabilité des services.
Les Quorums
(raft)
K8s utilise etcd comme base de données centrale. Etcd fonctionne à quorum :
Si tu as 3 nœuds etcd → quorum = 2
Si tu as 5 nœuds etcd → quorum = 3
Et ainsi de suite : quorum = (N / 2) + 1
➡️ Si le quorum n’est pas atteint, plus aucune écriture ne peut avoir lieu.
| Cas | Quorum utile pour… |
|---|---|
| Kubernetes (etcd) | Éviter corruption de l’état du cluster |
| Kafka | Gérer qui est le leader, assurer la cohérence des messages |
| Base de données répliquée | Assurer que la majorité a bien reçu les écritures |
| Élection de leader | Décider qui prend le contrôle sans conflit |
RBAC Authorization
L’autorisation RBAC utilise lerbac.authorization.k8s.io Groupe APIpour piloter les décisions d’autorisation, vous permettant de configurer dynamiquement les politiques via l’API Kubernetes.
Pour activer RBAC, démarrez leserveur API avec l’ —authorization-configindicateur défini sur un fichier qui inclut l’ RBACautorisateur ; par exemple :
manifest example:
apiVersion: apiserver.config.k8s.io/v1 kind: AuthorizationConfiguration authorizers: … - type: RBAC …
L’API RBAC déclare quatre types d’objets Kubernetes : Role , ClusterRole , RoleBinding et ClusterRoleBinding . Vous pouvez décrire ou modifier le RBAC. objets en utilisant des outils tels que kubectl, comme tout autre objet Kubernetes.
Voir doc pour en apprendre plus sur: Role, ClusterRole, RoleBinding et ClusterRoleBinding
Other orchestrator
Docker Swarm
Nomad
Tools
For Dev Environment
- Vagrant
- Docker Desktop
- Minikube (k8s)
- Minishift (k8s)
- Kind (k8s)
For Infrastructure Provisioning
- Terraform (preferable)
- CloudFormation for AWS
- CLIs (of respective cloud provider)
- Pulumi
For Configuration Management
- Ansible (preferable)
- Chef
- Puppet
- Saltstack
VM Image / Container Management
- HashiCorp Packer
- Docker
Helm
Helm est un gestionnaire de configuration et de paquets pour Kubernetes. Il permet de déployer facilement des applications complexes sur un cluster Kubernetes à l’aide de Helm Charts (graphes de déploiement).
Il offre de puissantes fonctionnalités de templating, prenant en charge la génération de templates pour tous les objets Kubernetes : Deployments, Pods, Services, ConfigMaps, Secrets, RBAC, PSP, etc.
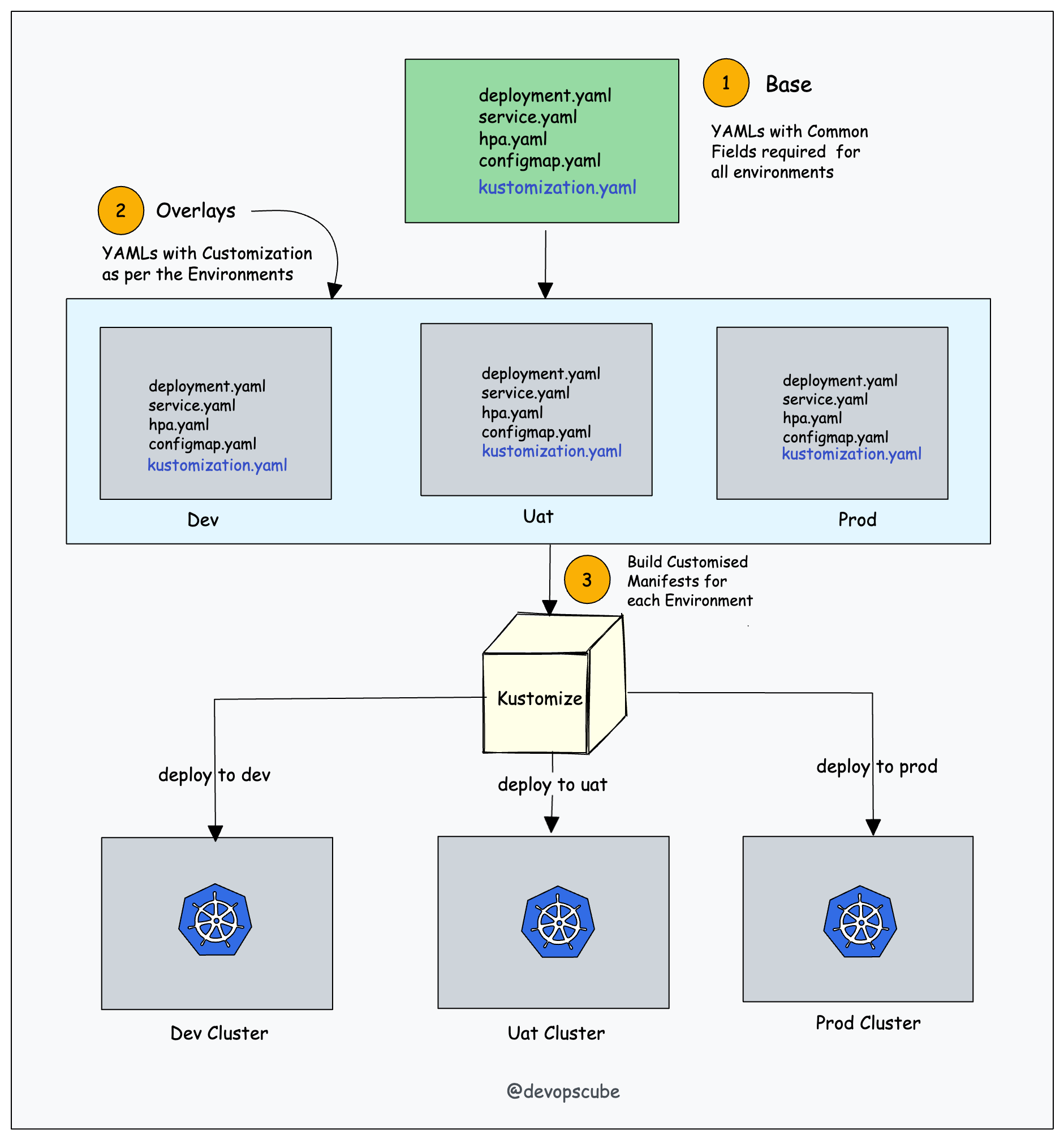
Kustomize
Kustomize repose sur deux concepts clés : Base et Overlays.
Avec Kustomize, on peut réutiliser des fichiers de base (fichiers YAML communs) pour tous les environnements, et y appliquer des overlays (patchs) spécifiques à chaque environnement.
Le processus de overlaying consiste à créer une version personnalisée d’un manifest, en combinant :
manifest de base + manifest overlay = manifest personnalisé
Toutes les spécifications de personnalisation sont définies dans un fichier appelé kustomization.yaml.
Terminology
- Node: A worker machine in Kubernetes, part of a cluster.
- Cluster: A set of Nodes that run containerized applications managed by Kubernetes. For this example, and in most common Kubernetes deployments, nodes in the cluster are not part of the public internet.
- Edge router: A router that enforces the firewall policy for your cluster. This could be a gateway managed by a cloud provider or a physical piece of hardware.
- Cluster network: A set of links, logical or physical, that facilitate communication within a cluster according to the Kubernetes networking model.
- Service: A Kubernetes Service that identifies a set of Pods using label selectors. Unless mentioned otherwise, Services are assumed to have virtual IPs only routable within the cluster network.
Ressources
Comprendre K8s dans le détails, la plupart des liens ci-dessous sont tirés de cet article Comprendre la concurrence RAFT Théorème CAP & concurrence Gestion de la planification avancée